Implementing CanCan and Omniauth with multi-authorization support and integration testing proved to me to be somewhat challenging. For the most part, I think the challenges reflect my lack of sophistication with Rails development, but there were a reasonable number of questions out on the web that reflected other people with similar challenges, so I thought I’d document what I’ve learned, and how I was able to get Capybara working with it all.
Uncategorized
Test Driven Development and COTS
COTS is traditionally taken to mean Commercial Off The Shelf. However, I’ve also heard it referred to Configurable Off The Shelf. This latter term more accurately describes a large class of systems implemented in business environments today. The package can largely be deployed as is, but typically has a significant number of configuration options to allow it to be more closely tailored to its target environment.
When preparing to deploy one such system earlier this year, a colleauge and I thought it would be interesting to leverage Microsoft’s Test Manager(MTM) to create and record test results covering the final testing of the product. Both of us being new to automated testing and things of that nature, we didn’t foresee the challenges we would face. The largest challenge was the lack of detailed reporting available at the end to use as documentation for compliance purposes. In addition, the system is not very supportive of stopping and test mid stream and continuing later. If you stop a test you frequently need to declare it a failure, even if the issue you were facing isn’t strictly speaking a failure. Of course, this sort of testing is not really what Test Manager was meant for (or any other code testing tool). The end result was that we decided to that we wouldn’t use MTM for similar activities in the future.
At the same time, I was working on another project that was all about code development, but where the significant code base had no tests written for it before. Typically, attempting to run tests against such code is likely to result in a bunch of errors, and very little, if any value. However, I was playing QA for an offsite developer, and I decided that it would be useful to have some predefined tests for me to run whenever the develope did a code check in. I turned out to be right. I didn’t have to rethink what steps to run through every time. I could also refine the test list, and hone it so that I was hitting all of the important parts.
As I was going through this process, it occurred to me that testing tools, and Test Driven Development (TDD) techniques could actually be of benefit during a COTS implementation process. Since tests in a TDD environment actually serve as a form of requirement, you can write up your tests either as a copy of an existing requirements document, or have the test list serve as the requirements document. Of course, the important point here would be to make the test titles suitably descriptive (as they frequently are in a TDD environment).
As configuration of the system progresses, you run all of the tests (skipping ones that you know haven’t been worked on yet), until you have all of your tests completed. This then tells you that you are ready to enter into the formal testing phase for compliance systems, or that you are ready to release. This also facilitates Agile implementation of a COTS system. As you progress through the various Sprints, User Stories turn into Test Cases, and as those cases test properly, you are done with a Sprint.
I haven’t actually attempted this yet, but it seems reasonable, so I will definitely attempt it.
Old Habits
I have written recently about my discovery of testing when developing code, and of test driven development. At the time, I was amazed at how well it revealed unused code as well as bugs in the code that is being used. Unfortunately, I have also discovered that testing is a discipline. Like any other discipline, it is one that you have to work at establishing, and you need to work to maintain it.
I came to a spot while working on the LiMSpec project where I was trying to develop some unique code, and simply stopped writing new tests, and completely avoided running the existing tests while I was busily “hacking.” I had reverted to my old bad habits established from 20 years of coding in everything from Assembly Language on up the complexity tree. Code, code, code, then maybe document, then maybe design. Test only when everything is done.
Surprisingly… okay, not surprising at all, I had broken various things in the process. The only way I knew this was when I ran tests to generate a coverage report. So I’ve now gone back and fixed the broken parts, and have extended the existing test suite. There is still more work to be done. I’d like to get close to 100% coverage, but am only at about 85% right now (I think it might actually be quite a bit higher as RCov seems to have missed many places where the code has been run in a test but is not being captured), and will seek to get there during the second release. In the meantime, I’m going to try to force myself to move much more toward the Test Driven Development approach – where the tests are written first, then the code written to pass the tests.
The Advantages of Being Too Big to Fail
The Wall Street Journal’s CIO Report tells us that SAP has finally accepted that their software has usability problems. While it is laudable that they have finally realized the problem, and equally laudable that they have decided to fix the problem, or at least attempt to, the fact that they have taken so long is something that many IT professional should think about.
I have blogged before about the importance of considering usability in systems as something important. Apple figured that out a long time ago, and they have become very successful. Many other companies weren’t so concerned, and have faded away, or are in the process of doing so. The advantage that SAP has is that they are literally too big to fail. Their installed base is so large that they can afford to wait until major customers start deploying non-SAP software in their environment to fix a fundamental flaw in their products.
The question should be whether your company is too big to fail. This question should be asked even if, especially if, your primary product is not software. As I noted earlier, many corporate IT groups are primarily concerned with deploying a solution, not deploying a usable solution that the customers need. What ends up happening is that IT fails to deliver additional value to the business. Large numbers of users don’t adopt the solution and much of the purported advantage of the solution is never realized. In addition, IT develops a bad reputation and future projects slow down or fail because of it.
In the 21st century, many employees have literally grown up with very usable technology (Apple, Facebook, Amazon, etc.). They are very productive when using these technologies and expect the same usability at the office. I don’t know how many times in the last few years I’ve heard someone say “I’d just like it to work as well as Amazon.” When the tools IT delivers are not that usable, they will find other ways to succeed. Typically, this is not a victory for either side. The user solution may be faster for them, but probably not as fast as a well designed solution, and likely their failure to use the deployed solution means that other value propositions are not being realized (such as data mining opportunities and the like).
What is sad about this story isn’t so much that SAP is a bit slow in figuring things out, but rather what it means regarding the numerous companies that use their software. How much inefficiency and waste exist in their customer’s organizations because the product is so hard to use? How much money wasted on excessive training classes for new users, how many miniature IT projects exist to provide workarounds? How many extra employees are required to manage the system vs. produce and sell product? I wonder how many of those organizations are too big to fail.
A fuzzy thing happened to me on my way to the cloud
If you’re at all involved with IT, you know that every other article you see these days seems to have something to do with cloud computing. Increasingly, these discussions are turning to the world of science. However, there is one group within this world that has remained fairly resistant to the cloud, and that is the FDA regulated group. Primarily, my familiarity is with the pharmaceutical and device industry, and that is, of course, where I see the most resistance. Typically, there are two major concerns voiced, one of control, and the other of security. I would like to challenge both of these concerns by questioning the underlying assumptions.
The first concern, that of control, is usually voiced as a desire to “know” who can be talked to if something goes wrong. That is, if the data is internal to the organization, you can cause the people charged with safeguarding the data endless amounts of grief if something happens to it. Perhaps (and I think this is the underlying assumption) you could even get them fired if something serious happens. If the people responsible for data safety are external (at, say, Amazon or Google), then you don’t have that sort of power. There are two problems with this perspective. The first has to do with motivation. Assuming that the people doing the job of protecting your data do so out of fear of losing their jobs (which they probably don’t), they are just as likely to lose their jobs for failure to perform at one company as at another. The owner of the data may have less direct impact on that, but realistically, the risk to the data guardian doesn’t really change. The bigger problem is the “so what?” problem. So what if you can get someone fired? Does that get your data back? Does it restore your access if it has gone down? Of course it doesn’t.
The real question needs to be what quality level you can expect from internal vs. external. By quality, I mean not only reliability and safety, but also cost. Let’s be honest, cloud companies typically have a much higher quality of infrastructure available for their data center than do any individual business whose primary job is not providing a data center. If you doubt that, go tour the data center in your company. In this day and age, even small companies can and do have robust data centers. However, compare what you have to what Google has. With a cloud solution, you can access such elaborate technology for a much lower cost than if you were to attempt to do the same yourself. While cloud outages are hardly unknown, are outages involving your internal infrastructure unknown? If you think about it, such outages and service interruptions are probably not that uncommon in your environment. They may not seem as big, as they don’t impact hundreds of thousands of users, but they are likely no less significant to your data and access to it.
In terms of talent available to you, either in a support or perhaps even customization role, you may find that the talent pool available from cloud vendors may be more substantial than what you are able to hire within your company. This may make your data not only more secure, but if you are having things customized or enhanced, you may find yourself more satisfied with the end results.
The other concern is one of security. Typically, this is the fear of the “open system”, by FDA definition (21 CFR 11.3(9)) a system where the access control is not by the same persons responsible for the data itself. Two points need to be made here. The first is that this regulation was written back in the days when there was the internet (still a relatively new phenomenon) and then there were the computers in your company, and the two were generally not connected. Now, when everyone’s internal system is attached to the internet, you may not have nearly as much control over access to your system as you think you might. In other words, you may be safer treating your system as an open system regardless of whether you own the servers or they are located in Googleville. Certainly, if you have employees accessing your data from their homes, you will employ all manner of additional security, and that has become relatively common.
The second point is that the additional requirements for open systems are that you have a means of encrypting data. That is all. Really. In fact, here’s the entire regulation: “Persons who use open systems to
create, modify, maintain, or transmit electronic records shall employ procedures and controls designed to ensure the authenticity, integrity, and, as appropriate, the confidentiality of electronic records from the point of their creation to the point of their receipt. Such procedures and controls shall include those identified in § 11.10, as appropriate, and additional measures such as document encryption and use of appropriate digital signature standards to ensure, as necessary under the circumstances, record authenticity, integrity, and confidentiality.” That is it. Today, encryption technology for transmitting data is as common as that https you’ll occasionally see in the URL bar of your browser. In other words, it isn’t much of a challenge. Otherwise, the same set of rules as for a closed system apply. Therefore, you’ll need to take the same care. You’ll want to audit and evaluate the systems in use by the cloud company, just as you would your internal systems. But there is really nothing additional you’ll need to do.
Now that I’ve said all this, I need to point out that contract terms need to be ironed out. Sometimes large cloud companies have less than ideal guarantees around up time and the like. You’ll also want to be sure that you are comfortable with what happens if the cloud company ceases operations, or you decide to not use them anymore. Where does your data go, and how easy is it for you to get it back? This can be easily overlooked and people can be burned by bad decisions in this area.
What I’m trying to get at with all of this is that we need to clear in the thought processes behind deciding on the cloud. I think to date, many of us have been driven by fear, and fear tends to lead to fuzzy thinking. That won’t get you to where you need to be.
I Have Seen the Light
At one point in an Orthodox Divine Liturgy, a hymn is chanted which starts with the phrase, “We have seen the true light…” While not of similar religious significance, occasionally programmers can have epiphanies that lead us to at least have a similar feeling.
For me, the true light I have finally seen is around testing and test driven development. While I’ve always supported testing – at least the sort of ad hoc testing most developers do while coding, and maybe a more thorough approach along the way by QA people, coupled with UAT at the end of the project, the notion of automated testing as you code has really not appealed to me. I didn’t get the point. Granted, I hadn’t really looked into how it was used, or why it was used – even though Rails builds a nice testing framework for you.
On the project I am working on that started out in appFlower, I decided that I needed to re-evaluate my traditional behaviors. It began with using a deployment tool for the app, which downloads the latest changeset from a version control system and deploys that to production. The tool also allows you to quickly and temporarily bring the site down while leaving a nice maintenance message. This will make deploying changes to production much cleaner than my former brute force approach of just copying everything up to the server, and adjusting a couple of the files so that it was running as production.
The latest re-evaluation was around testing. I researched why and how people were using Rails tests, and was intrigued after reading some online material, and watching this video:
The presenter introduced the notion of “Technical Debt”, basically legacy design and code (frequently dead code in my experience) that requires anyone expanding the system to continue using the old system architecture, simply because it is neither well documented, nor would you have a means of truly knowing if you broke something when you alter the architecture. I have lived, and am currently suffering with, such a system. A great amount of effort is spent coding around limitations, because touching the core code might have significant unintended, and often hard to discover, consequences.
So, last week, I started running at least the basic tests that Rails generates as you are building an app. I had to spend time dealing with the authorization and role based aspects of the app, which are a challenge to deal with in testing, but during I have already reaped the benefit of testing. I was amazed, for such a new app, exactly how much dead code, and ill conceived design decisions had already crept in. Writing test cases forces you to really think, at a detailed level, about how the application will respond to the user. I haven’t even started the process of testing the UI, but I plan on it, because this application is intended to go into production relatively soon with a narrow range of functionalities and then to expand over time. Using a more test driven approach should help this growth occur in a sustainable manner, and hopefully push the redo horizon out a bit further (the point at which the Technical Debt grows to a level that causes Technical Bankruptcy).
The Wilting of appFlower
I thought it would be useful to provide at least a brief postscript to the appFlower evaluation. We opted to leave it behind for most of the reasons I stated (in addition, when I wrote that post I had just submitted a couple of major questions/issues, to which I have not received a response, so the lack of support is seriously underscored). I’d have to go back and look at the relative time, but as I suspected, in probably no more than 10% of the time, I had a basic app running.
Most of the additional time I needed to spend was in upgrading my Rails IDE (yes, I’m lazy enough to use one), the version of rails on my machine, along with a number of other supporting tools, and then attempting to get the app running on my provider in a shared hosting environment. This last bit of time was useful, in that getting used to Capistrano for deployment was something new. I was able to get everything configured so that I could move all of the correct components to production when ready, but was having trouble getting the fastcgi script configured (the version of passenger that my host uses is way outdated, and the only alternative I have is to pay for a virtual private server so I can install everything myself). Bringing up appFlower on a server really would only take slightly longer than the time required to download the VM image, so this is an appFlower plus. On the flipside, I do not like the sense of real time editing of a production applications, so I’m not exactly sure how you can successfully avoid this.
The other large amount of time spent was on using a new authentication approach than I have before. Previously I used authlogic, but there is a relatively new gem called Omniauth which has providers to allow for authenticating with everything from a system specific user/password to Facebook, LinkedIn, Twitter, OpenID, etc. I was particularly interested in allowing a single user to have multiple authentication methods, so this took a time to figure out. The authorization facility available in appFlower, if you can actually get it working, does not allow for third party authorization. There are tools that allow you to do this with Symfony. This, of course, means that to accomplish anything significant you need to work in Symfony, not appFlower per se. If I was a php/Symfony expert, perhaps this would not be a big deal. Of course, if I was a php/Symfony expert, I suspect that appFlower would be an incredible enumberance, and I wouldn’t use it in the first place.
The actual time spent on the app in Rails itself has been fairly minimal, and now I can move along adding new features and capabilities, with a nice look and feel to the whole thing. I’ve also decided to focus more energy on using the Rails testing framework, which I will discuss in a future post.
My conclusion is that appFlower is marginally interesting but likely of little value over time. While it looks pretty, it has significant limitations that require an actual developer to overcome, so its primary market of non-developers doesn’t look to be well served.
That Blooming appFlower
Sorry, the best humorous line I could think of on short notice.
I’m working on developing an application for managing requirements and RFPs/RFIs for LIMS acquisition projects, and as part of that, I was asked to take a look at appFlower and use that to build the app. In the interest of documenting my findings with regard to appFlower, I figured it would be most useful to blog about things as I go along.
However, to begin, let me provide a little background as to what appFlower is. appFlower is a somewhat unique beast in that it is an application development framework built on… another application development framework. This other application framework is Symfony, a php framework somewhat akin to Rails for the Ruby development crowd. In the interest of full disclosure, I should reveal that I’m well acquainted with Rails, so forgive me if that colors any of this commentary.
As far as I can tell, there were a couple of goals behind the creation of appFlower. One was to shift from the extensive use of yaml to manage configuration in Symfony to the use of xml, which one can argue is the more broadly used standard. The second goal, I believe, was to provide a rich UI for creating the various forms, etc., that you might desire in a basic web application. Therefore, you can build some basic lists and data entry forms with a fairly nice UI, and the ability to add and edit records with effectively no programming. That in itself is worthy of a couple of gold stars.
One thing that it is important to realize when discussing rapid application development (RAD) frameworks is that they fail immediately on one key element of their basic sales pitch, “Build web apps in minutes”, or my favorite from the appFlower site, “Why write code that can be created automatically? Skip learning SQL, CSS, HTML, XML, XSLT, JavaScript, and other common programming languages (Java, Ruby and .Net)” This latter statement besides being incorrect, is also an example of the sort of verbal sleight of hand most commonly seen in political advertising. One might note when reading the above statement that they don’t mention PHP, which is at the heart of appFlower. You’d better know PHP if you want to do anything really useful here. You will also need to know CSS if you want the app to look any different that what you get out of the box, and for sure you will want to be able to deal with XML. You certainly won’t need to know Java, Ruby, or .Net, as those aren’t the languages of this framework (a somewhat disingenuous statement). I expect I’ll be writing javascript along the way as well. Oh, and you may not need to know SQL (we’ll see about that), but you will need to understand basic RDBMS concepts.
All application frameworks, and appFlower is simply no different, are intended to help seasoned developers move along more quickly by building the basic pieces and parts of a web application automatically. All that is left is adding in the additional functionality you need for your specific requirements. By building the framework, the learning curve is simply reduced for everyone. At the same time, there is a feature of these frameworks that can be frustrating. Frequently you will find that if you simply put a URL in with a keyword like edit, that the app just knows what you intended and you get the desired result. For instance, in appFlower, if you create an action and associate it with an edit widget, the app figures out from the context (if the action is associated with row of data it knows you want to edit, and if it isn’t it know you want to create a new row of data) what to do. However, you’ll never know when the app will or will not be able to figure out what you want until you try and get an error message. Which, by the way, is important safety tip #1, turn on debugging. Otherwise you will never have any idea of what is happening. Even at that, the messages may not be that helpful. Like my favorite, “Invalid input parameter 1, string expected, string given!” How silly of me to give the app what it expected.
As I was building a simple screen to add categories to assign to requirements, I wanted to add a delete button. So I looked for an example, and the only example exists in a canned plugin. In other words, I couldn’t find, even in the walkthrough for creating an app, the simple process of deleting a piece of data. Perhaps the appFlower team doesn’t think you should ever delete data. Typically, when you assign a URL to an action they tell you to just specify the filename for the widget you just created (these files are typically xml files). However, in the case of deleting, there is no widget, even in the plugin. So, I thought maybe the app simply knows if I say delete (like with the plugin), but that didn’t work. deleteCategory? nope. Finally I was able to dig through the code to find the right action class php file for the plugin, and was able to determine where the appropriate file existed that I needed to edit to create the action. Then I used the model code in the plugin to create the code I needed. In php. In other words, this is not some magical system like Access, or Filemaker, or 4D that allows you to quickly bring up a fully functioning app with no coding. You will need to code.
This takes me to the next issue, which is support. Support appears to primarily exist as a couple of guys who run appFlower who occasionally answer questions. Perhaps if I wasn’t using the free VM that I could download, it would be different. Paid support usually gets a better response. I’ve got a number of problems and questions, including the one about how to delete a row of data. Three days in and no response. Other questions/problems have been sitting in the queue for much longer. Don’t plan on a lot of help with this. Unfortunately, unlike Rails (and probably Symfony itself), there is not a robust community of users and experts out there available to help answer your questions at this point. The only way to figure things out is in the documentation.
There is an extensive documentation set and some nice examples. Unfortunately, the documentation lags development, and sometimes in a significant way. I attempted to setup up the afGuard plugin, which is for handling authentication and security. Unfortunately, if you follow the docs (there are a couple of different processes described) you will not be successful. For instance, widgets and layouts they claim exist, do not. It turns out you don’t need to copy anything yourself either, you can reference them where they are by default, and this is the recommended behavior. Recommended by the developer, at any rate, who happened to answer this question. The documentation tells you to copy the files elsewhere. I’ve tried a couple of times to get security working, but in both instances the app just stopped working. Since I couldn’t get any response to my posting of problems on the site, I deleted the VM and started over again.
I’m on my third time now, and am waiting to try afGuard again until later. I will also make sure to backup the app and the data before I start, so I can restore the work I’ve done without having to wipe the slate and start over. The latest rendition of the app is moving along nicely. Let me tell you what has been easy, especially since I’ve been so negative. Dealing with my own tables and widgets, once you read a bit through the docs and look at a couple of examples to understand the approach, I can generate, very quickly, a nice tabbed interface with lists and forms to edit. The framework get’s one to many relations, and if you put in a related field to edit, it will by default assume you want to create a drop down list with the description field from the other table (which most of the time is precisely what you want to do.) Adding and updating records, and creating those buttons is trivial. I now know how to delete records, so that code will be transportable. I don’t have it working perfectly yet. Apparently there is a template I need to create that will popup and let you know how things went in the delete attempt. I don’t think that is documented anywhere so I will have to see what I can figure out. Here is one page of the app as it stands right this second.
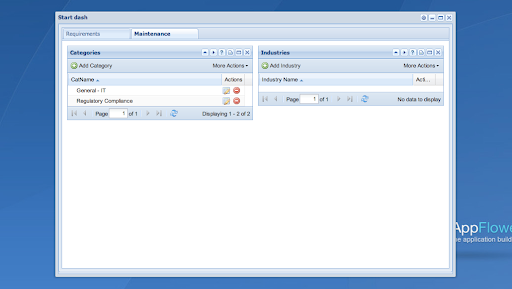
So, I certainly didn’t get this up in minutes. If I had left security out, perhaps that would have been closer to the case. The question is, did I save time vs. using straight Symfony or Rails? With Rails, I can say categorically, no. This is because I know Rails and I can get a basic app, including authentication, up very quickly. If I had used straight Symfony, I would have had to install the framework, then get used to the way it generates files, and get up to speed on PHP, which I hadn’t looked at in quite a while. So, appFlower may have saved some time there. Once I know the framework well, future apps will likely move along much faster, and maybe even faster than rails.
The Autodidact
The other day I had a individual request some pointers on where to go to learn about a topic that was ancillary to a project she would be working on. The question arose as to whether there was real value in that. Certainly, since she would merely be executing scripts, there is not a significant short term benefit to time spent learning about this topic.
On the other hand, given the organization and her general responsibilities, there will likely be long term benefit to a little time spent now. However, there is a more significant issue in view. In my experience, an individual who likes to spend time educating himself makes a very powerful team member. This willingness to self teach tends to result in stronger problem solving skills and greater overall creativity. Failure to support such behavior means a failure to develop your team (and in this case it’s not taking much of a manager’s energy), as well as potentially driving a strong contributor to find an environment which values this behavior more. Something to think about.
A Core Issue
The Wall Street Journal this week, published a piece about the impact of “bad apples,” or toxic, lazy, or incompetent employees on the work place. It makes sense that a bad employee affects an organization more than a good employee. It’s basically the second law of thermodynamics for corporations. There is a tendency toward maximum entropy (disorder), so the the bad employee is simply going with the flow. A good employee is fighting against that tendency.
I’ve seen this in action in the past, in a number of environment, both big and small. In smaller organizations, the problem is generally dealt with more rapidly, although there was one individual years ago who was hired on reputation, but who’s only skill appeared to be criticizing the work of others. This went on for a while until someone in management realized that he hadn’t actually produced anything, and then he was gone. In larger corporations, toxic or incompetent employees tend to stick around, in larger numbers, for a much longer time. There are a number of reasons for this, not the least of which is that HR and legal departments are extremely nervous. The slightest threat of litigation if not every i is dotted and t crossed. Therefore, elaborate processes are established, which allow the employee in question to just do well enough to not be terminated, but not actually become one of the strong employees. There are other reasons, as well, such as decisions being made fairly high up the management chain where the decision maker is too far removed from the actual operations, and a generally useless performance review process. I’ve even heard of situations where senior management makes ranking and merit increase decisions before evaluations have been written, thus ensuring that the direct supervisors have little input in the process and thereby eliminating one very effective tool for managing difficult employees.
What is interesting is that this situation, of a large number of bad apples, especially in larger organizations, came up at the end of last year, as I discussed here. The one issue I haven’t discussed regarding causes of the existence of bad apples, is that of training. There are plenty of bad apples who have absolutely no interest in improvement, but there are those employees who either start out wanting to improve, or wake up and smell the coffee and come to realize that they need to improve their skills. Unfortunately, especially in larger corporations, where actual process improvement to drive the lowering of costs is out of the question, the solutions are often the following: restrict travel, restrict cell phones, restrict training, and outsource. All of these force the short term improvement in the bottom line that drives most CEO’s. All of these, at the same time, can cripple in the long term.
So what does all of this have to do with the mission of InfoSynergetics? Well the first is simply a reality check. If one is going to engage in a project in any organization, especially a larger one, you have to be prepared to cope with the bad apples. I find it most useful to attempt to engage them head on. If they are toxic, don’t let them succeed with you. I had one situation where a somewhat toxic person involved with a project I was running would come in my office almost looking to pick a fight over some imagined slight. The more I refused to engage in either combat or becoming defensive, and merely sought to solve their problems, the quicker the relationship improved and the toxicity became less prominent. For employees who might not be very skilled, they present a worst case scenario from a systems standpoint. How can I design a system that will allow them to be functional in spite of their lack of skills? In some cases, the lack of skills is not actually in the area they get paid for, but more in the IT arena. While these people hardly fit the category of bad apples (they are usually very effective in their disciplines), they represent a similar challenge from a design perspective – and thus can help in the creation of a truly useful system.
So, I guess that the moral of the story is that while bad apples can be a drain on an organization, from a project and systems perspective, we can find them to be, if not beneficial, then at least not inhibitory in successful project execution. We need to anticipate their presence, and be prepared to adapt appropriately.